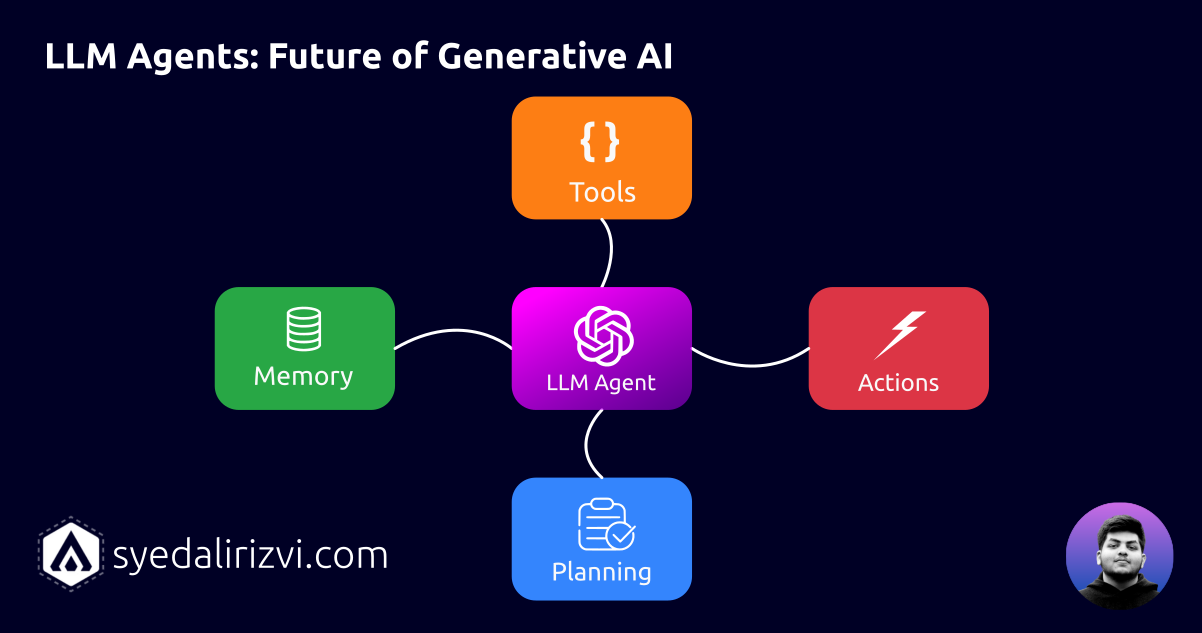
Recently, State-of-the-Art (SOTA) language models such as OpenAI’s gpt-3.5-turbo, gpt-4, llama, Mixture of Experts models such as Mixtral’s mistral-8x7b have demonstrated exceptional capabilities when it comes tasks like code synthesis, Natural Language Understanding (NLU) and Natural Language Generation (NLG), the main reason being the volume of data they have been trained on, we have been witnessing a sudden technological shift and adaptation of these models and without ignoring the fact that if you have been active consumer of these models, either as an end-user or a developer, you might have already noticed some of their limitations as well....