Recently, State-of-the-Art (SOTA) language models such as OpenAI’s gpt-3.5-turbo, gpt-4, llama, Mixture of Experts models such as Mixtral’s mistral-8x7b have demonstrated exceptional capabilities when it comes tasks like code synthesis, Natural Language Understanding (NLU) and Natural Language Generation (NLG), the main reason being the volume of data they have been trained on, we have been witnessing a sudden technological shift and adaptation of these models and without ignoring the fact that if you have been active consumer of these models, either as an end-user or a developer, you might have already noticed some of their limitations as well.
Let’s face it, Large Language Models (LLMs) cannot be relied upon in isolation for building robust AI applications, which has lead many developers ending up utilizing them only as core controllers sitting behind structured pipelines implemented as wrappers for these models for them to effectively generate relevant content.
In this article, I will be covering the main limitations of standalone Language Models and the modern techniques which have emerged lately to mitigate these issues.
Limitations
Alright, so what do we know about large language models so far ? They are great at generating content, from code snippets to textual data, but as
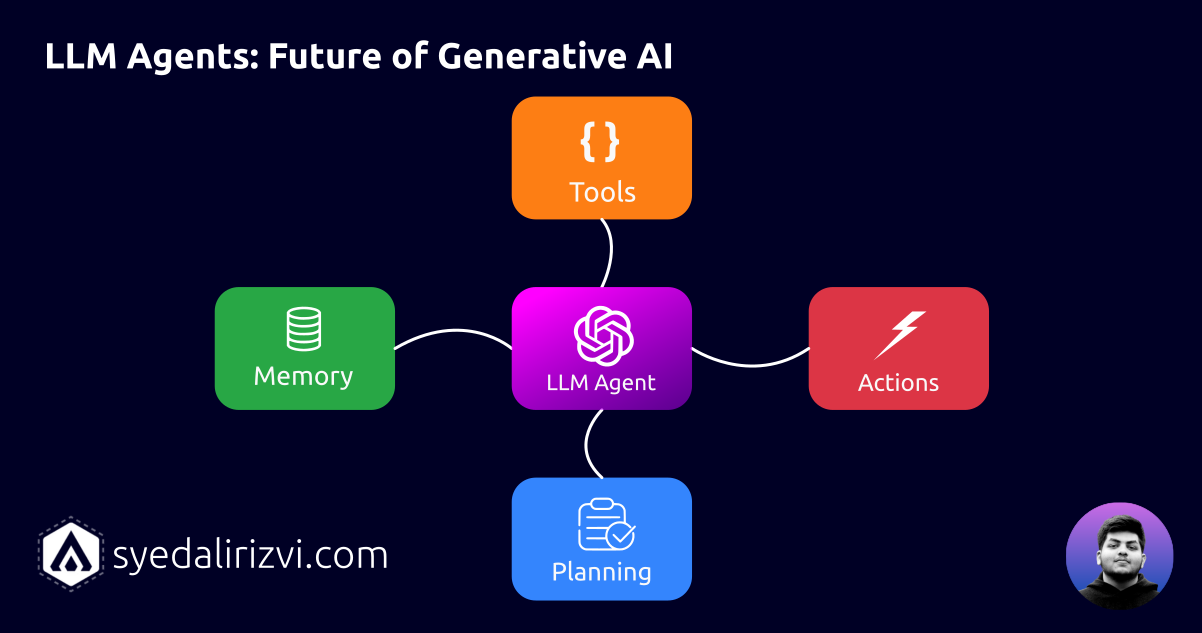
Now based on the above findings, we know langauge models although demonstrating exceptional capabilities are still “limited”, in terms of:
- Contextual Memory
- Planning
- Performing Actions.
- Access to External knowledge.
LLM Agents: The modern approach
Here’s a sample prompt:
You are an <Role>
Think step by step before answering